


LLM Comparisons - Benchmarks and Leaderboards
OpenAI, Google, Anthropic, DeepSeek and XAI have recently released new versions of their LLMs and in this article I look at benchmarks, comparisons and leaderboards.

Background
Large language model (LLM) vendors are in a competitive arms race and in 2025 so far, we have already seeing many new models released.
These frontier models push the boundary of what has been possible so far, utilising more compute, more data, more parameters with innovations in pre-training and post-training.
To demonstrate improvement and superiority, LLM vendors or third-parties publish the result of benchmarks.
In today’s article I look at a few of the popular benchmarks and leaderboards.
LLM Benchmarks
LLM Benchmarks generally have the following properties:
Static or Live
Ground truth or Human preference
Mode: Text, Audio, Image, Video
Use Case; Creative Writing, Math, Coding, …
The most common LLM benchmarks are Static Ground truth, meaning the evaluation test questions are a known dataset and have objectively correct answers. Such test evaluations are inexpensive and re-producible to run, but they can suffer from over fitting contamination, making the results less representative of real world use.
Live refers to a continually changing set of tests, harder to contaminate but more expensive to create, evaluate and compare.
Human preference is self evident, such tests do not have canonical correct answers and so require a human to evaluate and grade the responses.
Let’s take a look at a few of the more widely known benchmarks and leaderboards.
LM Arena
Also known as ChatBot Arena, is a crowd sourced AI benchmarking platform hosted by researchers at UC Berkeley SkyLab and LMArena.
It is Human Preference based and Live and available here.
The Leaderboard tab currently shows the following Top 10 models.

Rank, with Grok-3 and GPT 4.5 ranked joint first
Arena Score, 1412 and 1411 for the above two
95% Confidence Interval of the Arena Score
Votes for the model
Organisation and License type
A number of the models have ‘Preview’ as part of the name, these and some others in the list are not currently generally available, e.g. GPT 4.5 has only just started being rolled out to ChatGPT Pro, the $200 pm plan.
This leaderboard changes most weeks as new models are released and it is derived from “Crowd-sourced Battles”.
Anyone can go to the Arena (battle) tab, enter a prompt, hit enter to send to Model A and Model B, compare the response side by side and vote for the winner. After which the name of the models are exposed.
It’s great fun, I recommend giving it a try, when you are bored with reading about AI… (better done on a laptop than on a mobile).

As of 2-Mar-02025, over 211 models and 2.7 million votes have been registered.
The leaderboard also has filters for Category of Use, so you can select rankings for Math, Creative Writing, Coding or Hard Prompts to name a few, which as you may expect, significantly change the rank order.
Those of you interested in technical details, can find the Chatbot Arena research paper here.
SEAL Leaderboards
These can be seen here.
There are a number of different leaderboards, (for a more limited set of LLMs than LM Arena), which are very interesting, so lets show a few of these as of today.
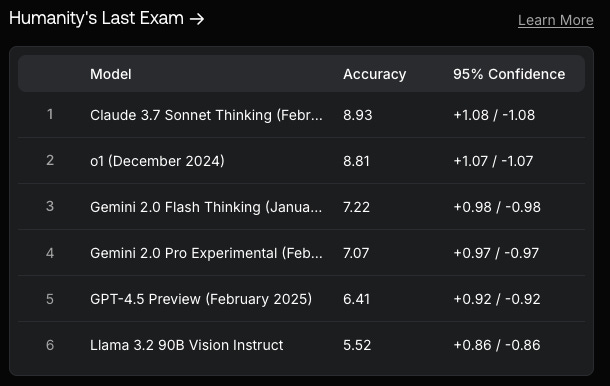
I like this one, Humanity’s Last Exam, which is described as “2,700 of the toughest, subject-diverse, multi-modal questions designed to be the last academic exam of its kind for AI. HLE is designed to test for both depth of reasoning (eg. world-class mathematical problems) and breadth of knowledge across its subject domains, providing a precise measurement of model capability.”
So questions, whose answers are not going to be found on the Internet or the training dataset for LLMs.
Not surprisingly, the accuracy scores for the best LLM’s are only in the single digit percentages.
So hope for us humans yet!
At least collectively, given the vast knowledge required to get a good score on HLE is way beyond a single person, let alone a small team.
More HLE details are here, the research paper and the dataset.
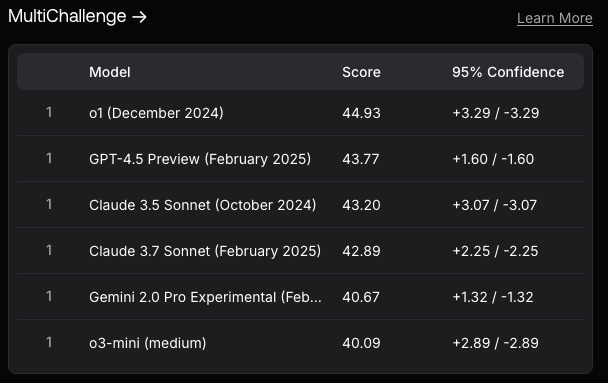
Ranking multi-turn conversations with humans, details here.

Agentic tool use, so chaining multiple tool calls together to solve tasks, details here.
MMLU, MATH, GPQA
Standard benchmarks, often seen in the literature include:
MMLU, Massive Multitask Language Understanding, a test covering 57 tasks including maths, US history, computer science, law and more. For details see github and paper.
MATH, a dataset of 12,500 problems from leading US maths competitions, for details see github and paper.
GPQA, Graduate-level Google-Proof Q&A Benchmark, consisting of 448 multiple questions written by experts in biology, physics and chemistry, with the goal that experts with PhDs in one these sciences would get 65% accuracy. For details see github and paper.
While there is no comprehensive website with all standard benchmarks for popular models, LLM vendors themselves release the benchmark scores of their models to demonstrate the improvement over their prior releases.
Or they can be run by anyone with access to the models and datasets for the benchmarks.
The following from this site, shows the improvements over the last 5 years for the MMLU benchmark, with recent models achieving > 87%.

The following from this site, shows the improvements over the last 4 years for the MATH benchmark, with recent models achieving > 88%.

While the below chart from lastexam.ai shows the above 3 benchmarks and HLE for a few popular LLMs.

More Benchmarks
Needless to say there are benchmarks for specific categories, such as Coding (SWE-bench) and Safety, as well as domains such as Legal, Medical and Finance.
But those are topics for another day.
There are other Leaderboards, see Hugging Face for Open LLM Leaderboard and others.
And it goes without saying, there are numerous studies and papers comparing different aspects of model use and performance.
As example, I liked BIS Working Paper No 1245, which examined AI agents for general tasks by evaluating the results of playing Wordle (6 chances to guess a 5 letter word).
Learnings
LLMs are improving all the time.
Benchmark scores are regularly published.
These quantify and showcase model improvement.
Leaderboards rank LLMs by benchmarks.
There are many specific benchmarks e.g. Coding, Math, Writing, Image, …
Take your pick.
Rankings may help you in deciding which LLM to use. However other factors such as specific tool use (e.g. Internet query for new results) are likely to be more important than the score or ranking.
Still in a competitive race, it is good to keep an eye on rankings.
You don’t want to end up using an LLM that falls way down in the rankings.